MagiAttention: Defining the Performance Ceiling for Long-Context Distributed Attention
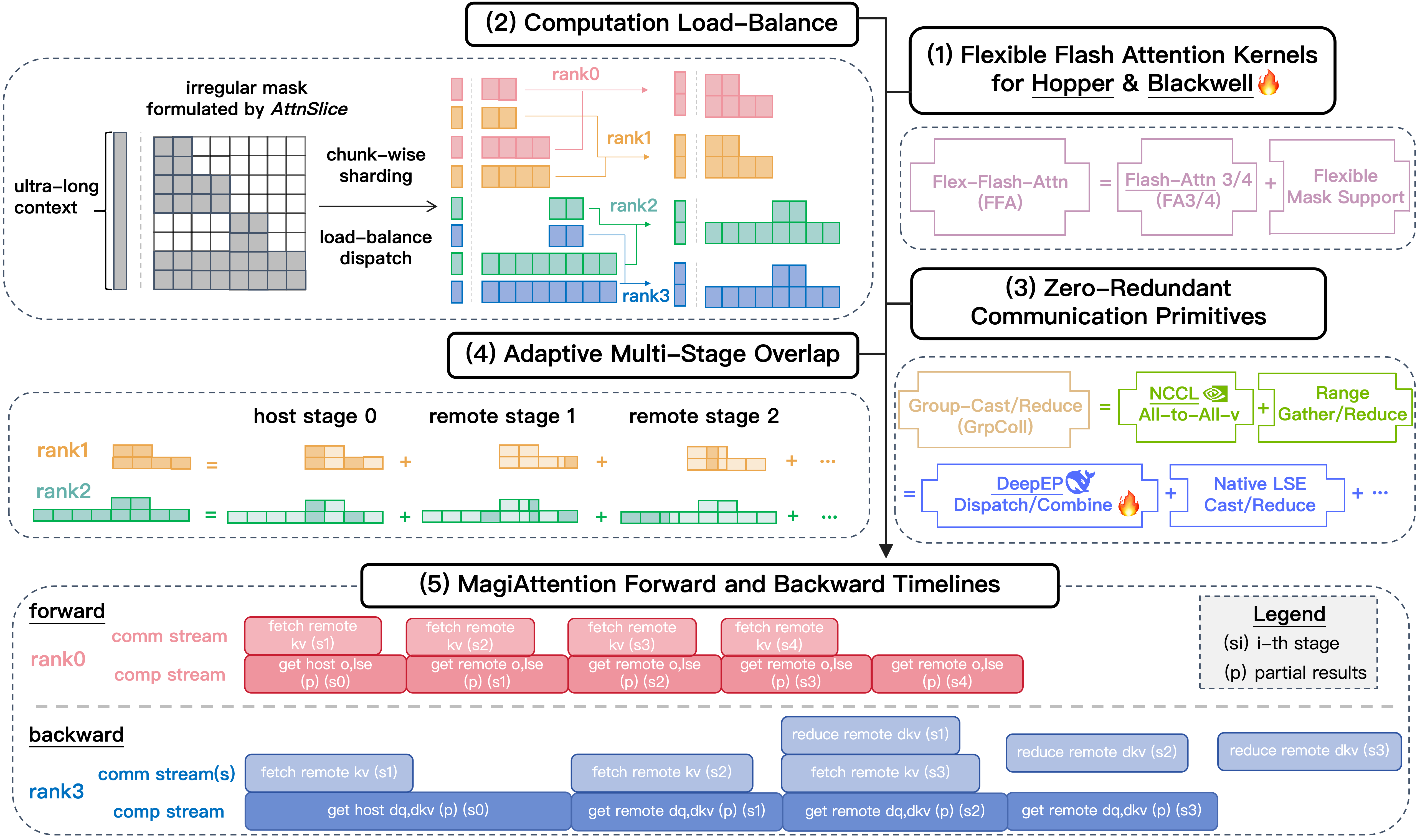
Overview of MagiAttention: Empowering ultra-long context training in (5) via: (1) mask-flexible kernels (FFA), (2) load-balanced sharding (Dispatch Solver), and (3) zero-redundancy communication (Group Collectives) with (4) adaptive multi-stage overlap.
The demand for ultra-long context window (reaching 4M+ tokens) is reshaping the landscape of Large Language Models and Video Generation. However, as sequences grow, researchers face a "double whammy": the quadratic complexity of Attention compute and the massive communication overhead in distributed clusters.
Moreover, modern algorithms introduce heterogeneous and irregular masks (e.g., Block-Causal, Patch-and-Pack) that break the assumptions of standard kernels, leading to load imbalance and wasted compute.
MagiAttention is a high-performance distributed attention (Context Parallelism) engine designed to shatter these bottlenecks. By co-designing flexible kernels with a system-level orchestration layer, MagiAttention delivers linear scalability and SOTA throughput across Hopper and Blackwell architectures.
Core Design Philosophy
MagiAttention is built on four technical pillars that coordinate to ensure no GPU cycle is wasted:
- Flex-Flash-Attention (FFA): A mask-flexible kernel that decomposes irregular masks into distributable units called
AttnSlice. It maintains Flash-Attention-level MFU while supporting arbitrary, complex masking patterns. - Dispatch Solver: A high-precision scheduler using a Min-Heap greedy algorithm to shard heterogeneous masks across CP ranks, ensuring perfectly balanced workloads and eliminating idle "bubbles."
- Zero-Redundant Communication: Replaces traditional, redundant Ring-P2P or All-to-All schemes with specialized
GroupCastandGroupReduceprimitives. - Adaptive Multi-Stage Overlap: A dynamic pipelining strategy that senses the compute-to-communication ratio to overlap stages effectively, hiding communication latency even in bandwidth-constrained environments.
What's New in v1.1.0: The Blackwell Era
With the release of MagiAttention v1.1.0, we transition from single-architecture optimization to a full-stack, multi-platform ecosystem.
🚀 Pioneering Blackwell (B200) Support
We've introduced the FFA_FA4 backend, tailored for the NVIDIA Blackwell architecture.
- HSTU Function Representation: Supports arbitrary masks on B200 without major changes to the FA4 core logic, maintaining performance within 5% of standard masks.
- Efficient Block Sparsity: A high-performance
create_block_maskkernel that prevents OOM by parsing masks on-the-fly instead of materializing them. - Instruction-Level R2P Optimization: Uses Register-to-Predicate (R2P) tricks to batch-set hardware predicates, eliminating the bottleneck of element-wise mask checks in the softmax warp.
- Minimized Memory & Latency Footprint: Features CSR compression for mask metadata and FFI-accelerated kernel launches, ensuring peak memory efficiency and ultra-low overhead even in ultra-long context scenarios.
📡 Native Group Collective Kernels
Inspired by DeepEP, we've implemented native CUDA kernels for group communication that outperform traditional All-to-All-v implementations.
- Kernel Fusion: Fuses data re-layout (Range-Gather/Reduce) directly into the communication kernels, cutting down D2D copy overhead and kernel launch latency.
- RDMA De-duplication: Implements a "NVLink-replaces-RDMA" strategy. Data is transferred across nodes only once via RDMA and then redistributed via high-bandwidth NVLink internally, reducing cross-node traffic by several folds.
🧠 Advanced Algorithmic Synergy
V1.1.0 provides native support for the latest architectural innovations:
- Muon QK-Clip: Returns
max_logitsdirectly from the kernel for efficient distributed reduction. - Learnable Attention Sink: Built-in kernel support for sink mechanisms to enable stable long-context windowing.
- Trainable Sparse Attention: Ongoing optimizations for dynamic, sparse masking patterns (like DeepSeek-V3/NSA).
SOTA Performance Benchmarks
MagiAttention v1.1.0 defines the new performance ceiling on both H100 and B200 clusters.
-
Kernel Level: While standard kernels drop significantly in throughput when facing irregular masks (Varlen Block Causal), FFA maintains near-constant performance, offering a "mask-agnostic" compute experience.
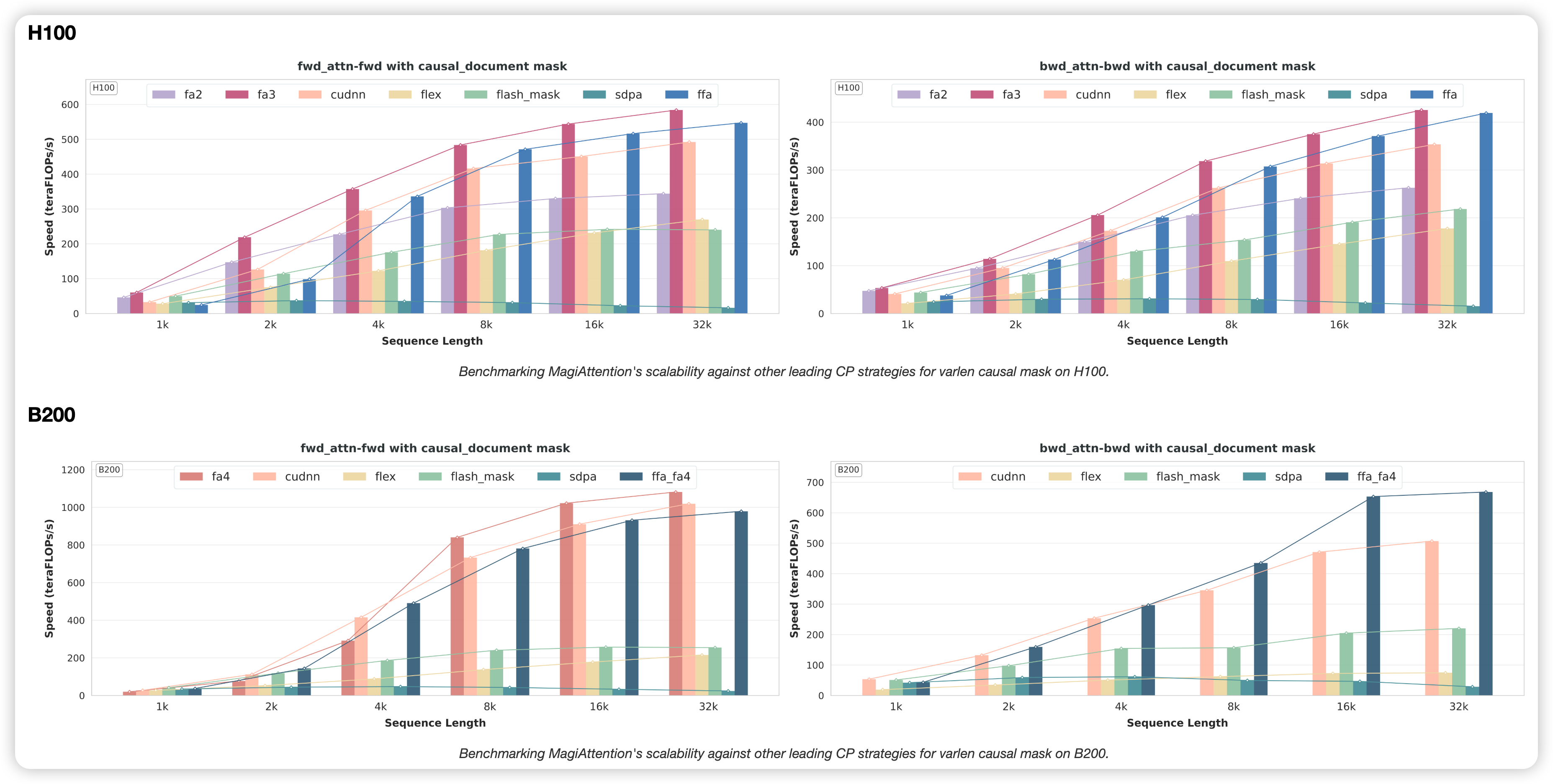
-
Distributed Level: In Varlen Causal scenarios, MagiAttention demonstrates superior near-linear scalability. With the Native Group Collective backend, the performance advantage widens as the CP size scales, effectively neutralizing the communication bottleneck.
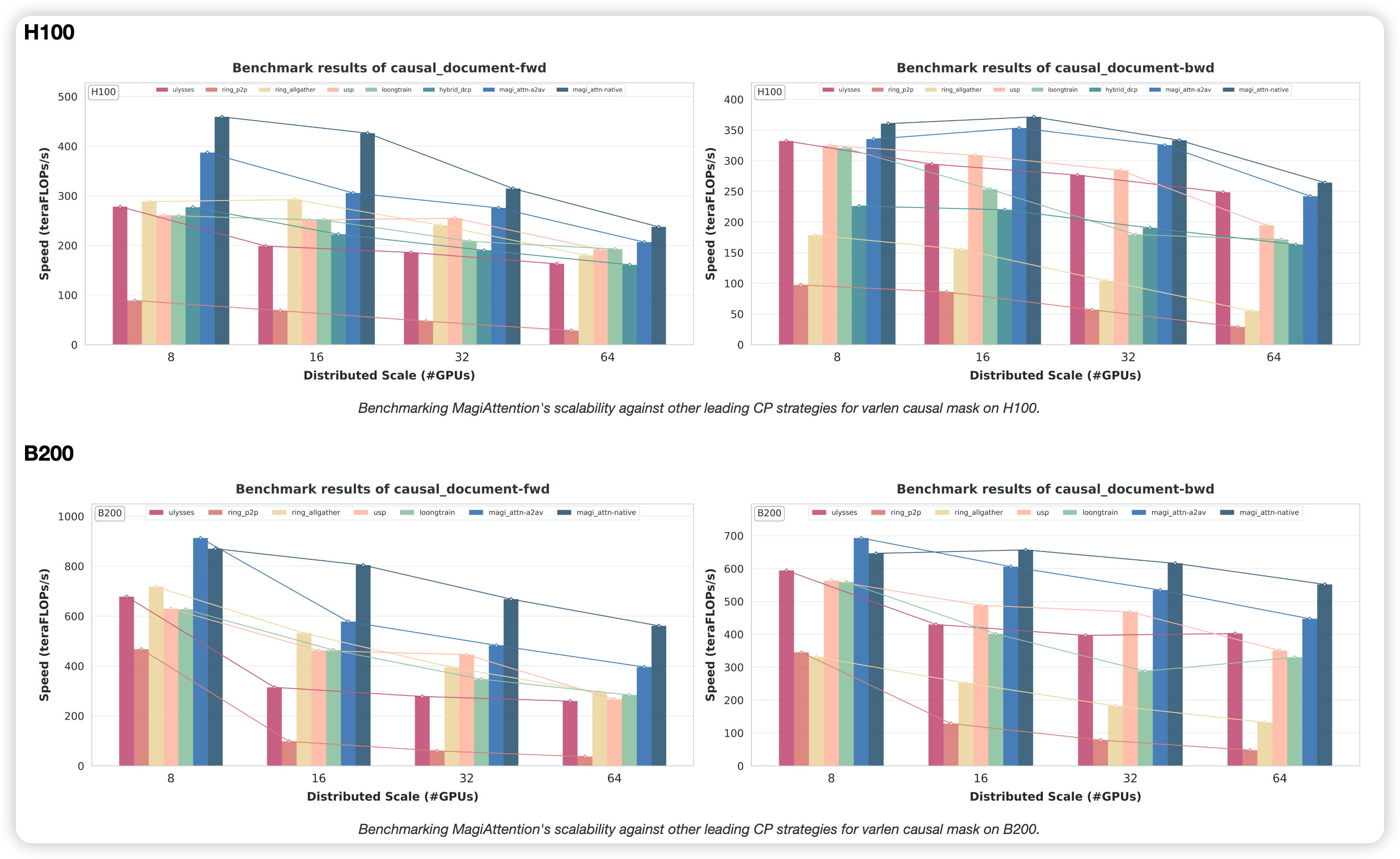
Get Started
MagiAttention is open-source and ready to power your next-generation long-context models.
- GitHub Repository: SandAI-org/MagiAttention
- Documentation: Full Installation & User Guide
- Technical Deep-Dive: Read the v1.1.0 Release Blog
Empowering the world's longest contexts with the world's fastest attention.