MagiCompiler: Break the Boundaries of Local Compilation for Large Models
Abstract
Large model developers often face a painful dilemma: optimize for speed, or save memory?
Pushing for maximum speed typically leads to Out-Of-Memory (OOM) errors, while aggressive memory-saving tactics severely degrade compute efficiency due to frequent synchronization and pipeline bubbles. While native torch.compile is user-friendly, it falls short when handling complex cross-layer optimizations and FSDP memory management.
To completely eliminate these pain points, today we are officially open-sourcing MagiCompiler, a plug-and-play, unified compilation framework for both training and inference, deeply optimized on top of torch.compile.
MagiCompiler shatters the boundaries of traditional local compilation by achieving Whole-Graph capture during inference and FSDP-Aware Whole-Layer compilation during training.
More importantly, we introduce the innovative concept of "Compiler as Manager." Upgrading the compiler from a mere "operator optimizer" to a global manager, it fully takes over computation scheduling and memory lifecycles, providing a system-level solution to the compute and memory walls.
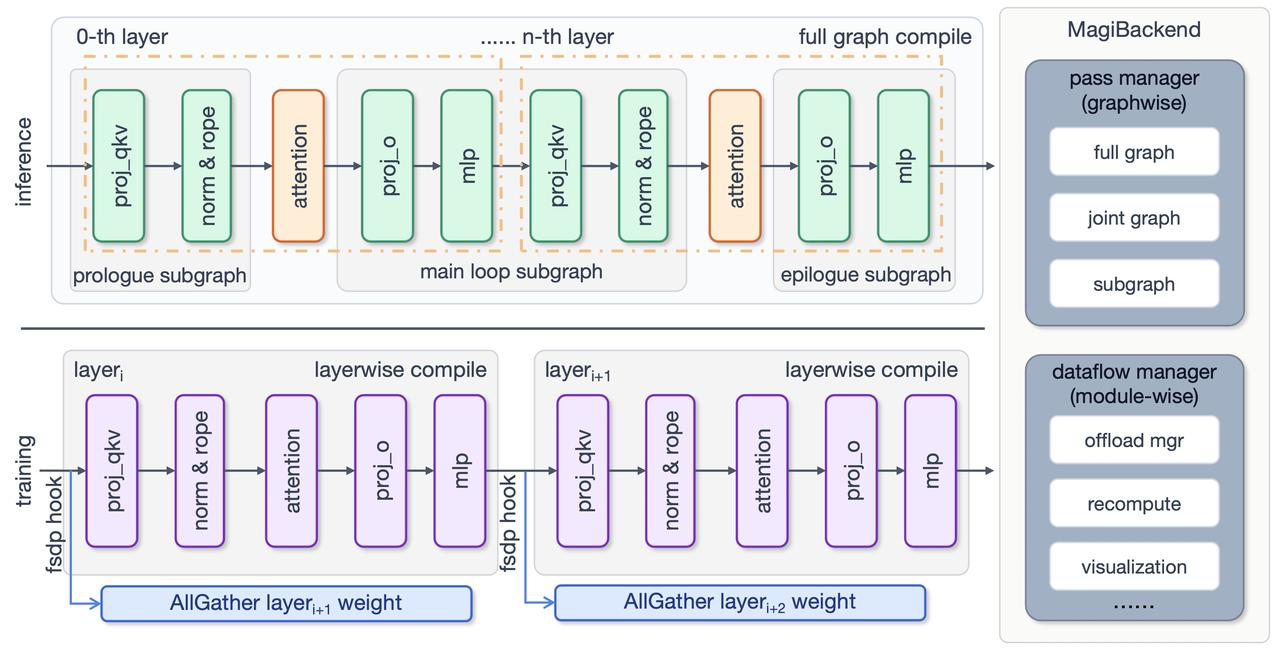
Under the Hood: Global Scheduling That Breaks Boundaries
MagiCompiler's impressive performance comes from three core breakthroughs in its underlying architecture:
- Breaking Compilation Boundaries: Whole-Graph and Whole-Layer CompilationTraditional compilation often suffers from frequent Graph Breaks caused by complex Python logic. We have fundamentally changed this paradigm:Inference Phase (Whole-Graph Capture): Captures the entire computation graph, maximizing the operator fusion space within Transformer blocks.Training Phase (FSDP-Aware Whole-Layer Compilation): Leveraging FSDP's characteristic of "full single-layer weight residency" during forward/backward passes, it treats a single Transformer Layer as the compilation unit. This empowers the compiler to perform aggressive cross-operator fusion, drastically reducing Kernel Launch overhead and Global Memory I/O.
- Memory Magic: Heuristic RecomputeTraining large models typically requires developers to manually insert
torch.utils.checkpointto control VRAM—a tedious process that rarely yields optimal results. We introduce a smart, context-aware graph partitioner:Zero Manual Intervention: The framework automatically analyzes the computation graph, identifying and prioritizing the retention of outputs from compute-intensive operators (e.g., MatMul, Attention).
- Inference Phase (Whole-Graph Capture): Captures the entire computation graph, maximizing the operator fusion space within Transformer blocks.
- Training Phase (FSDP-Aware Whole-Layer Compilation): Leveraging FSDP's characteristic of "full single-layer weight residency" during forward/backward passes, it treats a single Transformer Layer as the compilation unit. This empowers the compiler to perform aggressive cross-operator fusion, drastically reducing Kernel Launch overhead and Global Memory I/O.
- Zero Manual Intervention: The framework automatically analyzes the computation graph, identifying and prioritizing the retention of outputs from compute-intensive operators (e.g., MatMul, Attention).
- Squeezing Bandwidth: JIT Extreme Offload SchedulingTo tackle memory bottlenecks, we implemented an exceptionally elegant trade-off scheduling engine:High-ROI Residency: Based on profiling data, it greedily pins the most "cost-effective" weights in the limited GPU VRAM.Just-In-Time (JIT) Ultimate Prefetching: The scheduler reverse-engineers a precise prefetching timetable. It pulls weights at the absolute "last millisecond" before computation, ensuring the GPU never hoards unnecessary weights, thereby completely eliminating pipeline bubbles.
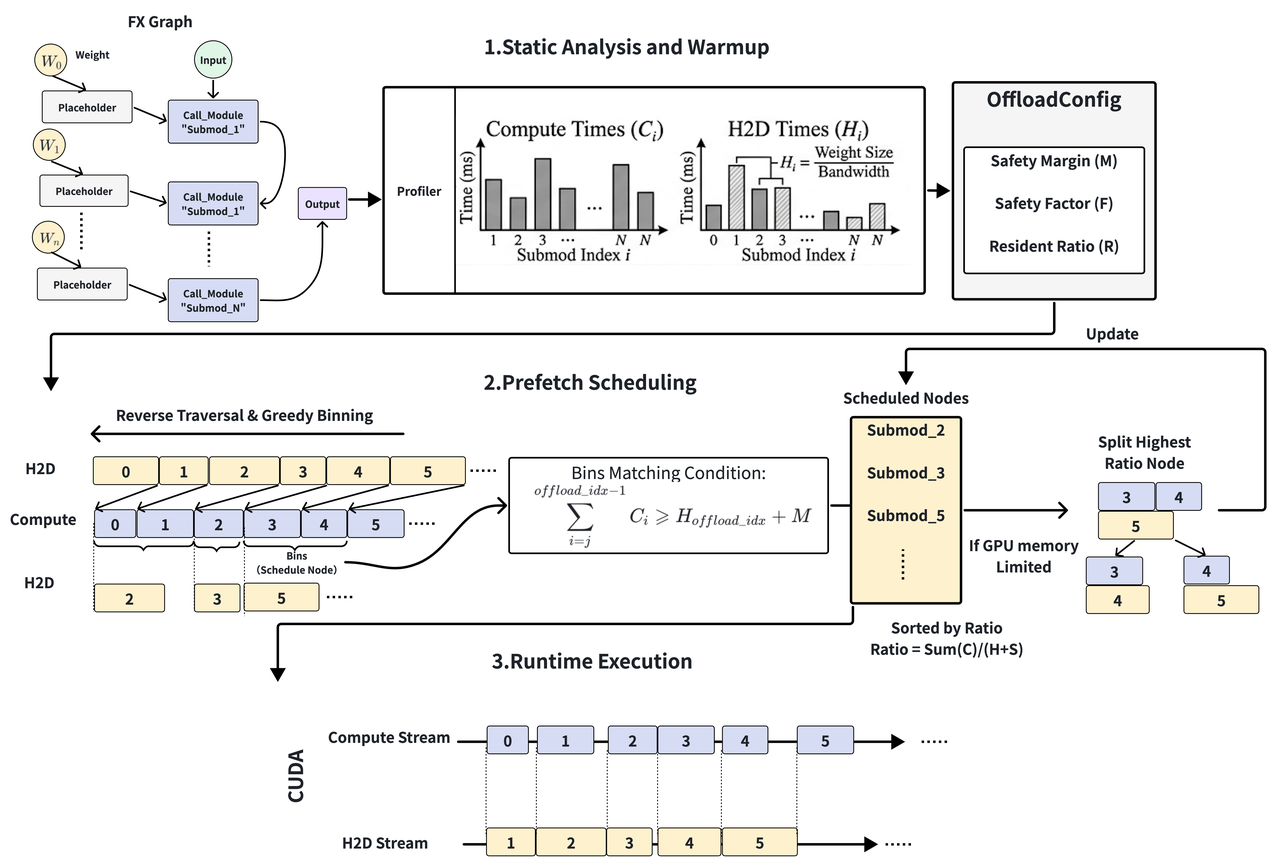
- Extreme VRAM Squeezing: For memory-intensive operators, it automatically triggers recomputation during the backward pass. This fundamentally compresses peak VRAM usage without compromising throughput.
- High-ROI Residency: Based on profiling data, it greedily pins the most "cost-effective" weights in the limited GPU VRAM.
- Just-In-Time (JIT) Ultimate Prefetching: The scheduler reverse-engineers a precise prefetching timetable. It pulls weights at the absolute "last millisecond" before computation, ensuring the GPU never hoards unnecessary weights, thereby completely eliminating pipeline bubbles.
Benchmarks: A Truly Free Performance Lunch
Thanks to its global scheduling, MagiCompiler delivers outstanding results out of the box in both training and multimodal inference scenarios:
🎯 Training: Skip the Low-Level Tuning, Maximize Baseline Throughput
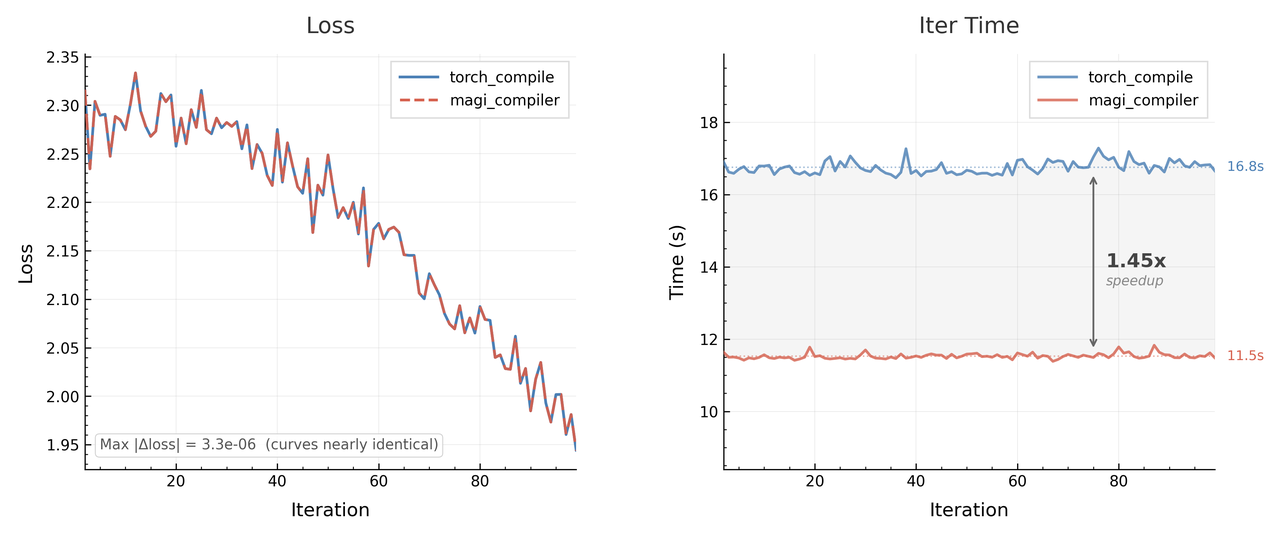
In the fast-paced world of large model R&D, algorithm engineers need to quickly validate model architectures. They don't have weeks to spend on low-level kernel fusion, manual pipeline orchestration, or fine-tuning memory recomputation. MagiCompiler's core value is providing a high-throughput baseline for algorithm experiments almost instantly.
Without manually tweaking any low-level logic, MagiCompiler automatically fixes severe CPU scheduling bottlenecks and operator fragmentation in the Baseline. This directly brings a 45% speedup in training. At the same time, thanks to the heuristic recompute strategy, the memory peak drops by 6.2%, and the model accuracy aligns perfectly with the Baseline. It gives developers a production-grade, highly efficient validation environment with basically zero mental burden.
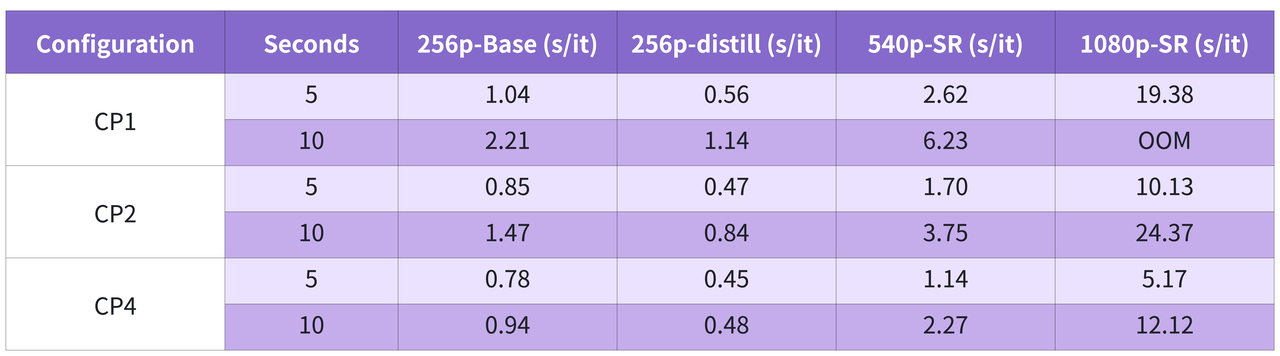
🚀 Inference: Breaking SOTA Bottlenecks for Multimodal Models
In multimodal video generation scenarios, MagiCompiler shows extremely solid hardware generalization:
-
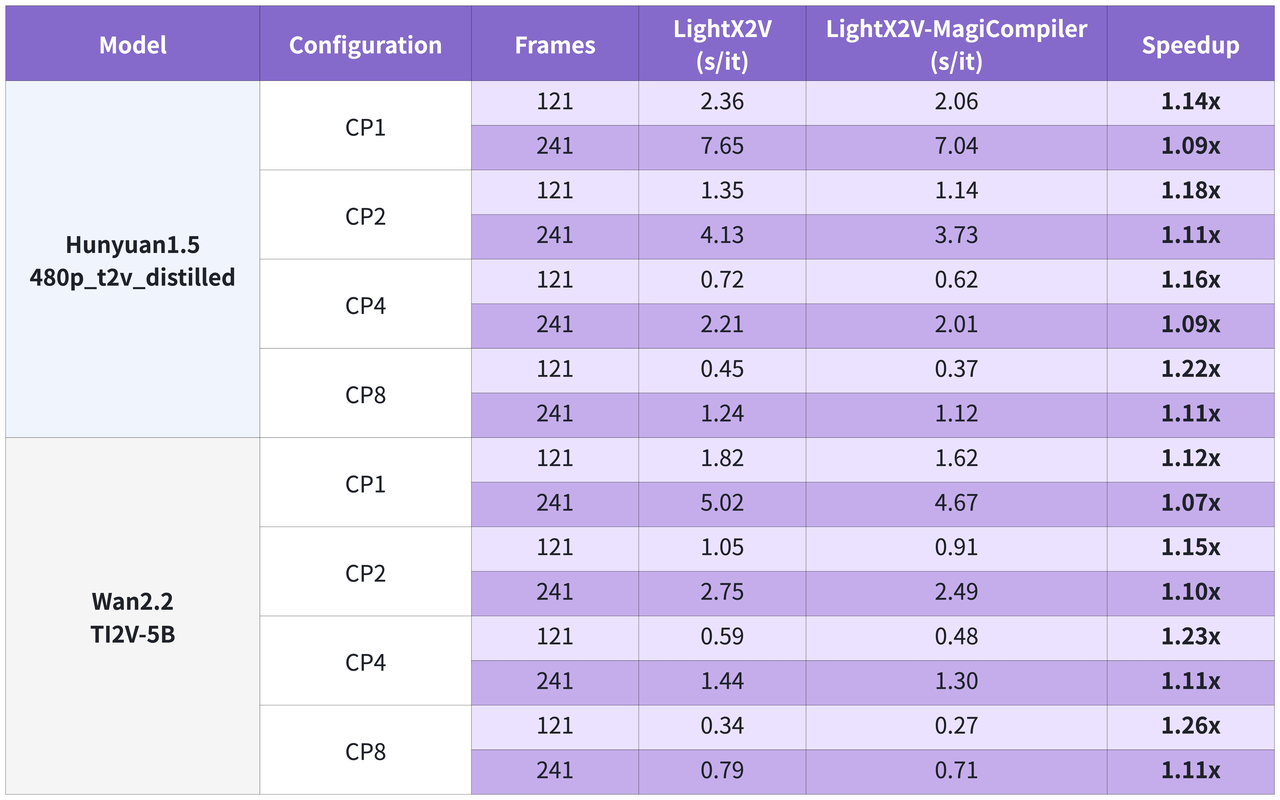
H100 Extreme Acceleration: When running mainstream open-source video generation models on a single NVIDIA H100, MagiCompiler achieves further breakthroughs compared to current SOTA solutions (like LightX2V), with an extra speedup of 9% to 26%.
-
RTX 5090 Near Real-Time: Thanks to the JIT Offload scheduling engine, even when facing massive models like daVinci-MagiHuman on GPUs with strictly limited VRAM like the RTX 5090, it can still achieve near real-time inference speeds.
Minimalist Experience: One Line of Code, Plug and Play
Powerful low-level performance doesn't mean a complicated setup. MagiCompiler is designed to be highly developer-friendly. You only need two decorators to get everything working.
1. Basic Compilation Enhancement:
No need to rewrite your model's source code. Just use @magi_compile to decorate your TransformerBlock with one click:
from magi_compiler import magi_compile
import torch.nn as nn
@magi_compile
class MyTransformerBlock(nn.Module):
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.layers(x)
2. Custom Operator Registration: If you're using customized operators like FlashAttention or MoE, you can easily register them to seamlessly integrate into the smart recompute strategy:
from magi_compiler import magi_register_custom_op
@magi_register_custom_op(
is_compute_sensitive=True, # 标记为计算密集,重计算时优先保存输出
is_subgraph_boundary=True, # 在此切分计算图
)
def my_custom_attention(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor) -> torch.Tensor:
...
🔍 Bonus: Making the Black Box Transparent MagiCompiler comes with a powerful built-in introspection toolchain. All the hidden compilation artifacts (decompiled bytecode, kernel code, guard conditions, and graph break tracing) will be saved as human-readable python files and visual charts. This hugely reduces the headache of dealing with underlying infrastructure, making the normally terrifying task of compiler debugging much simpler.
Conclusion & What's Next
MagiCompiler is breaking the boundaries of traditional compilers. It not only shows the huge potential of torch.compile moving toward global scheduling, but it also provides an indispensable infrastructure piece for the large-scale deployment of LLMs and multimodal architectures.
Currently, MagiCompiler is fully open-source. Moving forward, our team will release more practical demos and best practices covering both training and inference scenarios. We will continue to lower the barrier to entry for large model infrastructure development, contributing truly "out-of-the-box" performance dividends to the AI community.
GitHub Repository: https://github.com/SandAI-org/MagiCompiler/ (Feel free to drop by, try it out, and leave a Star!)