Scaling Video Diffusion Models with MoE
Video generation is entering a new scaling stage. Longer duration, higher resolution, richer motion, synchronized audio, and stronger controllability all require more model capacity.
For video diffusion, one of the core scaling pressures comes from sequence length. Compared with text, a video sample contains many more tokens: spatial patches across multiple frames, often combined with audio, text, reference images, or other conditioning signals. Under dense scaling, increasing model size means every token must pass through the full larger model. As video duration, resolution, and frame rate grow, this makes it increasingly difficult to scale model size aggressively in both the training side and inference side.
Training stability is another constraint. Video diffusion models see different feature distributions across denoising timesteps; unified video/audio/text modeling introduces heterogeneous token types; and visual tokens are often highly correlated across space and time. As models grow larger, these factors make training more sensitive to initialization, precision, routing balance, and distributed-system behavior.
MoE[1,2] is a natural direction for model scaling: it can increase total model capacity without increasing active compute proportionally. But making MoE work for video is not as simple as replacing dense MLPs with sparse experts. Video-scale sequence length and training instability changes the bottleneck. Communication, routing balance, and numerical stability all become first-order design constraints.
In this blog, we share our approach to scaling video diffusion models using a communication-efficient MoE design and a stability-driven training recipe. Together, these techniques enable us to scale models to the tens-of-billion parameter range while keeping training efficient and stable.
Communication-Efficient MoE for Video Model
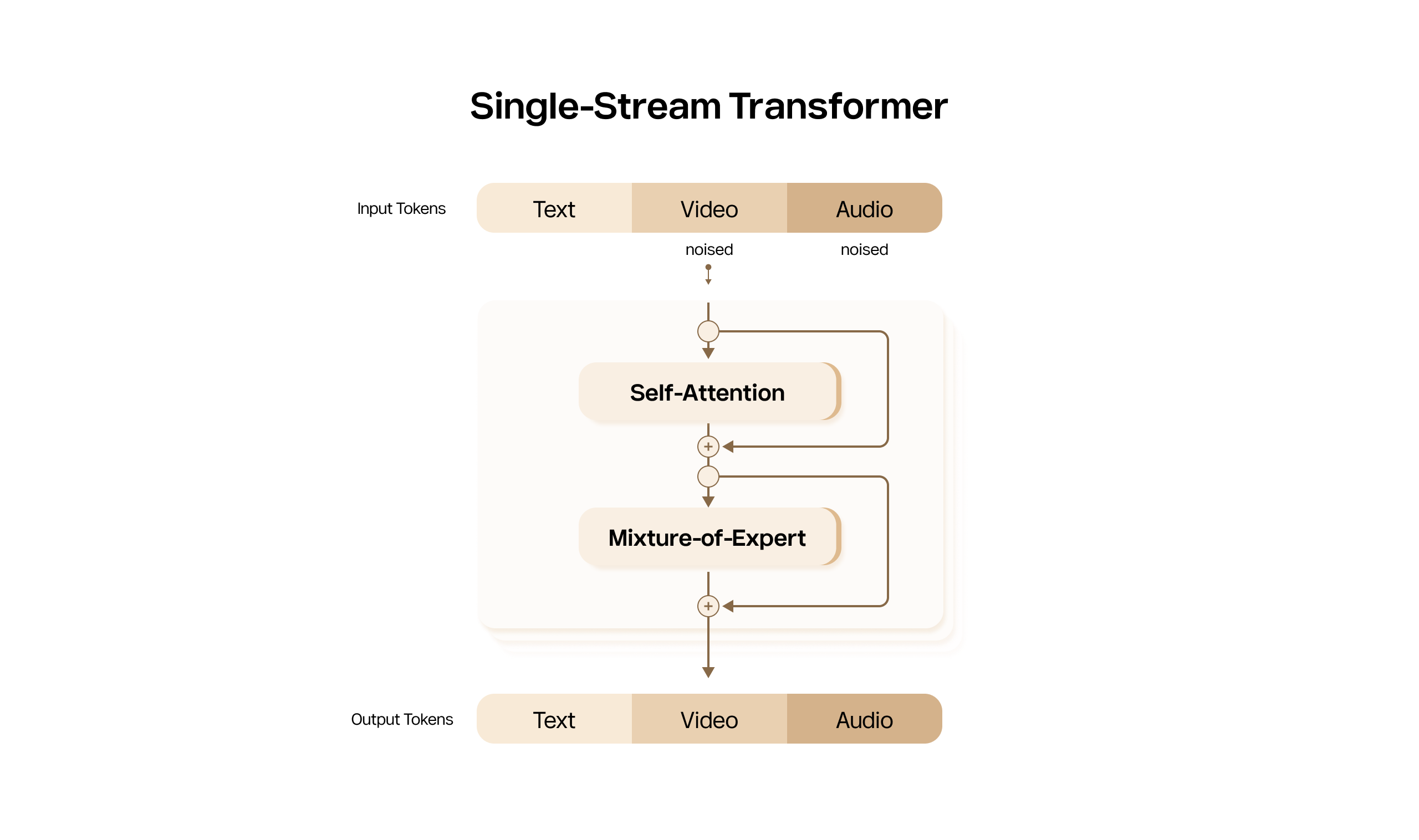
We start from a simple and efficient single-stream diffusion Transformer backbone[3]. In this design, text, video, and audio tokens are processed together in one unified token sequence using self-attention only. This avoids much of the architectural complexity of multi-stream or cross-attention systems, making the model easier to optimize at the infrastructure level. This is also a natural fit for MoE. Since the model already represents video, audio, and text as one unified sequence, sparse expert layers can be introduced into the Transformer stack without changing the overall modeling interface.
The key challenge is that standard LLM-style MoE is not directly optimized for video workloads. In a standard expert-parallel MoE system, tokens are routed to experts distributed across devices. Each token may be dispatched to multiple experts, computed remotely, and then gathered back. A simplified view of the dominant communication term per MoE layer is:
where is the sequence length, is the number of activated experts, is the communication payload size.
This is not meant to be a strict implementation-level formula. Real communication cost also depends on expert placement, parallel group size, load balance, capacity padding, kernel implementation, and whether the system is dropless. But it captures the key issue: when sequence length is large, the communication multiplier from top-k expert routing becomes expensive.
For video diffusion, this cost is amplified. Each training sample contains long spatio-temporal token sequences, and routing patterns can vary across denoising timesteps, modalities, motion regimes, and visual regions. As a result, standard MoE can easily become communication-bound: the bottleneck shifts from expert computation to token routing, dispatch, and all-to-all communication.
Our MoE design is built specifically for this regime.
Without exposing the internal mechanism, the high-level idea is to make expert communication less dependent on dynamic token routing. Through carefully designed routing constraints and expert placement, we reduce the amount of cross-device communication induced by routing, improve load balance, and make the communication pattern more predictable.
Conceptually, the dominant communication term behaves more like:
The important point is not the exact constant, but the scaling behavior: compared with conventional token-dispatch MoE, the dominant cross-device communication is much less sensitive to , expert count, and routing imbalance.
This does not mean expert parallelism disappears. Expert parallelism is still part of the system. The difference is that it is used under a more constrained and better arranged communication pattern, so the system avoids the typical failure mode where increasing sparse capacity creates disproportionate communication overhead. The MoE method we build on is designed to address exactly these issues: communication growing with activated experts, load imbalance, and data-dependent communication.
This difference matters more for video than for text. Since video already has a large , any extra communication multiplier is magnified. By reducing routing-related communication and improving expert load balance, our MoE design moves large video MoE training away from a communication-bound regime and closer to a compute-bound regime.
To sustain this benefit in practice, we optimize the MoE system stack together with the model design. Dispatch, expert computation, kernels, and parallel execution are treated as one integrated path rather than as independent expert MLP calls. This system-level optimization is essential for maintaining high hardware utilization as sequence length, expert count, and model size increase.
Stability-Driven Scaling Recipe
Communication efficiency solves only part of the scaling problem. Large video MoE models must also train stably.
In practice, MoE introduces several failure modes: unstable routing, imbalanced expert usage, overloaded experts, precision sensitivity, activation outliers, and occasional loss spikes. These issues become more serious in video diffusion because the model sees heterogeneous inputs across space, time, modality, and denoising timestep.
We therefore use a stability-driven scaling recipe. The main idea is not to add stability fixes after the model becomes unstable, but to make stability a first-class constraint throughout architecture design, numerical design, training setup, and experiment monitoring.
Activation control. Large video diffusion models can produce activation outliers, especially when sequence length, model width, and multimodal conditioning are scaled together. We use activation cutoff to control extreme values and prevent rare spikes from destabilizing training.
Precision-aware training. Not all operations are equally safe under low precision. We use a carefully tuned mixed-precision strategy: compute-heavy operations remain efficient, while numerically sensitive parts of the model are protected. This includes routing computation, where small numerical differences can change which expert receives a token.
Timestep sampling. Diffusion timesteps correspond to different training regimes. Early noisy steps and late refinement steps produce very different feature distributions. We tune timestep sampling to avoid over-stressing particular denoising regimes and to make large-scale optimization smoother.
Optimizer choices. We use Muon[4,5] as part of the large-scale optimization recipe. In our setting, it is one component of the broader stability stack rather than a standalone solution.
The common thread is that we treat training health as a primary signal throughout scaling. We monitor not only final quality or throughput, but also loss spikes, activation scale, expert load, router behavior, precision sensitivity, and system utilization.
With this recipe, our large-scale runs remain effectively zero-spike. Loss curves stay smooth, expert usage remains balanced, and scaling to larger parameter counts does not introduce fundamental optimization failures.
Takeaways from Scaling Video MoE
Communication becomes part of the model design
For video diffusion, MoE cannot be treated as a drop-in replacement for dense MLP layers. Video has a much larger token volume than text, and routing-dependent dispatch can quickly dominate training time.
Once communication becomes the bottleneck, adding more experts no longer automatically improves the scaling trade-off. The model may have more capacity in principle, but the system may fail to deliver that capacity efficiently.
This is why our MoE design is built around video-scale sequence length. Routing constraints, expert placement, load balance, dispatch, expert computation, and parallel execution need to be considered together from the beginning.
Stability drives the scaling process
In large video diffusion models, instability often appears before quality saturates. Loss spikes, activation outliers, unstable router behavior, expert imbalance, and precision sensitivity can all stop scaling before the model reaches its potential.
Our experience is that stable scaling does not come from a single trick. It comes from a stability-driven recipe: activation cutoff, precision-aware training, timestep sampling, optimizer choices such as Muon, and continuous monitoring of expert load, activation scale, router behavior, and system utilization.
The important lesson is methodological: stability should not be treated as a post-hoc debugging step. For large video MoE, stability has to guide the scaling process from the beginning.
Scaling reduces the need for post-training repair
Scaling also changes the role of pre-training. In smaller video models, many failures remain after pre-training: broken motion, unstable details, and weak temporal consistency, and poorly composed concepts. Post-training methods are then often needed to suppress these artifacts and steer the model toward cases it can handle reliably.
Pre-training is primarily a mode-covering process: the model is trained to represent the full data distribution, not only the easiest or most likely regions. In this sense, it is closer to forward-KL-like optimization. When capacity is limited, this objective is difficult to satisfy. The model may cover many modes only imperfectly, leading to visual artifacts.
Post-training often plays a different role. It is closer to mode-seeking, backward-KL-like correction: it pushes generation toward regions where the model already performs well and suppresses cases that expose its weaknesses. This can improve perceptual quality, but it does not fully solve the representational limits of the base model.
At larger scale, this balance changes. With enough capacity and stable optimization, the mode-covering stage becomes much more effective. The base model can direct generate high-quality videos during pre-training, and post-training becomes less about repairing artifacts and more about preference alignment, controllability, and product-specific behavior. Therefore, improving the pre-trained distribution itself has a larger impact than relying on post-training to filter or correct failures after the fact.
[1] DeepSeekV3 Technical Report, 2024
[2] Qwen3 Technical Report, 2025
[3] Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model, 2026
[4] Muon: An optimizer for hidden layers in neural networks, 2024
[5] Muon is Scalable for LLM Training, 2025